How to Make an AI Model A Practical Guide
A practical guide on how to make an AI model from scratch. We cover data prep, model selection, training, evaluation, and real-world deployment.

So, you're ready to build your first AI model. The process boils down to defining a problem you want to solve, gathering the right data, and then training an algorithm to make decisions based on that information. It’s how you turn raw data into a practical tool that can automate work, spot trends, or even create new content.
Laying the Groundwork for Your First AI Model
Building an AI model isn’t just for big tech companies anymore. It’s become a surprisingly accessible way for creators, marketers, and businesses of all sizes to tackle very specific challenges. At its heart, an AI model is just a program trained to find patterns in data. Think of it less like some unknowable magic and more like a skilled apprentice you're teaching to do a single job really, really well.
The journey from a vague idea to a working application follows a well-trodden path. Before we get into the nuts and bolts of how to make an AI model, it helps to understand this high-level roadmap.
The Core AI Development Workflow
The whole process can be broken down into a few key stages. You have to start by clearly defining what you want the AI to do. Are you trying to predict which customers might leave? Or maybe you need to automatically sort support tickets by urgency? A crystal-clear problem statement is the most important first step you can take.
Then comes the data. This part is critical—your model will only ever be as good as the information it learns from. This phase is all about collecting the right data and, just as importantly, cleaning it up. That means fixing errors, dealing with inconsistencies, and rooting out any hidden biases.
This image lays out the fundamental workflow for building a model from concept to execution.
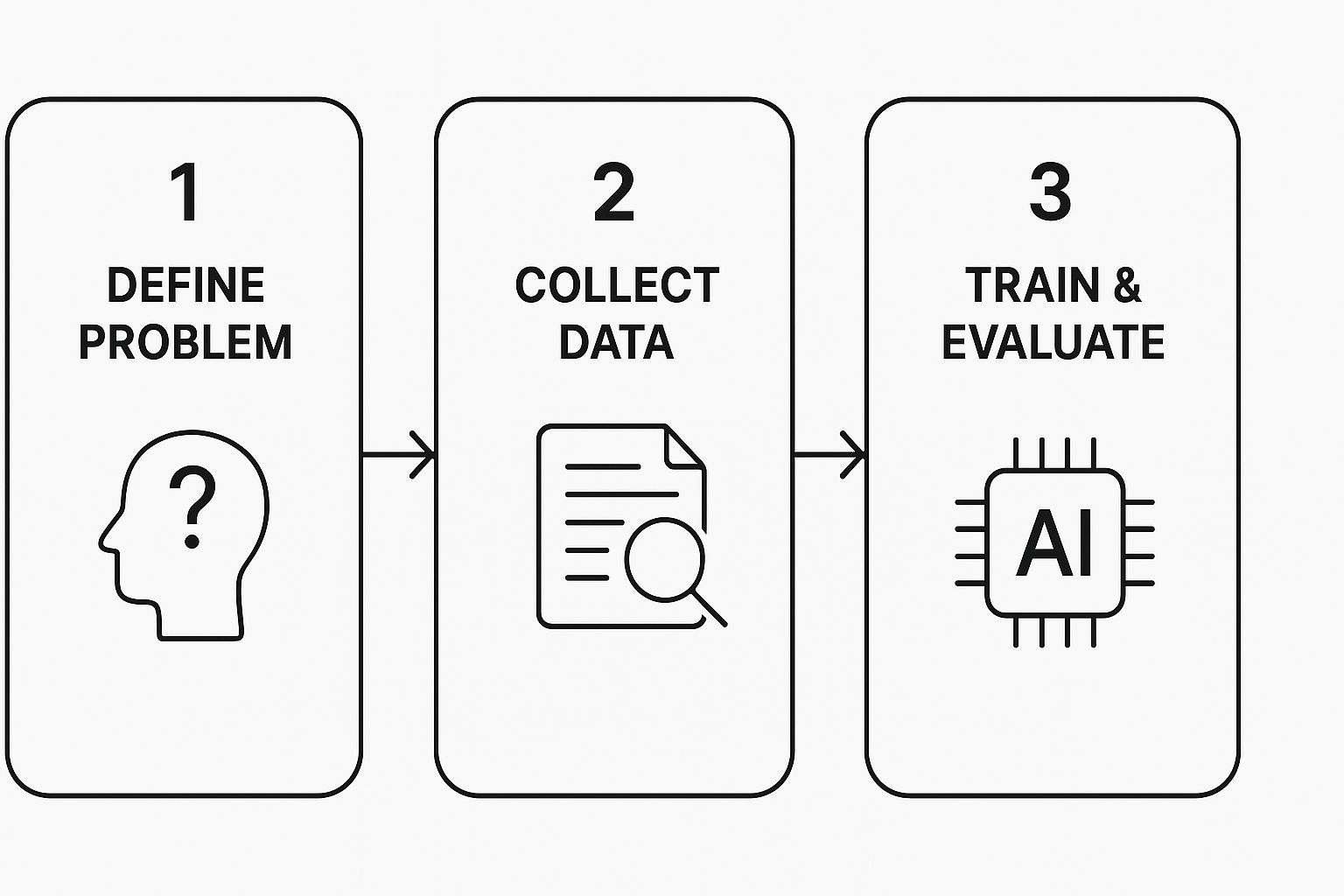
As you can see, the stages build on each other. A solid foundation in defining the problem and preparing your data is absolutely essential for a successful model.
To give you a clearer picture, I've put together a table that summarizes the entire lifecycle.
The AI Model Development Lifecycle at a Glance
This table provides a high-level summary of the core stages involved in creating an AI model, from initial concept to final deployment.
| Stage | Primary Goal | Key Activities |
|---|---|---|
| Problem Definition | Clearly state the objective and success criteria. | Identifying the business need, defining what a "good" outcome looks like. |
| Data Collection | Gather all relevant data needed for training. | Sourcing data from databases, APIs, or public datasets. |
| Data Preparation | Clean and format the data for the model. | Handling missing values, removing duplicates, feature engineering. |
| Model Selection | Choose the right algorithm for the job. | Comparing different model types (e.g., regression, classification). |
| Training | "Teach" the model by feeding it the prepared data. | Running the algorithm on the dataset, adjusting model parameters. |
| Evaluation | Test the model's performance on unseen data. | Measuring accuracy, precision, and other relevant metrics. |
| Deployment | Make the model available for real-world use. | Integrating the model into an application or API. |
Seeing it laid out like this really highlights how each step logically flows into the next. Get the early stages right, and the rest of the process becomes much smoother.
Why Build an AI Model Now
Honestly, there has never been a better time to jump in. The global AI market is booming—it was valued at around $279 billion and is expected to climb to nearly $391 billion soon. Some forecasts even see it hitting $1.8 trillion by 2030. This isn't just hype; it's being driven by real adoption, with over 78% of companies already using AI in some way. You can dig into more of these AI adoption insights on webandcrafts.com.
All this growth means more tools, better platforms, and a huge number of pre-trained models are now at your fingertips, which seriously lowers the barrier to entry. Your project doesn't need to be massive to make a real difference.
Key Takeaway: The process of making an AI model is iterative. You'll cycle through training, testing, and refining your model multiple times to improve its performance before it's ready for real-world use.
Getting Your Data Ready for Prime Time
Every powerful AI model starts with one thing: great data. You've probably heard the old saying, "garbage in, garbage out," and in machine learning, it's the absolute truth. The quality of your final model is a direct result of the hard work you put in right now, so let’s roll up our sleeves.

This whole phase—what we call data preparation—is often the most time-consuming part of the entire project. But trust me, this is where you can make the biggest difference. Cutting corners here will just lead to headaches later when your model struggles to learn anything useful.
Finding and Gathering Your Raw Materials
Before you can start cleaning, you need the data itself. The right source really depends on the problem you're trying to crack. For example, if you're using a platform like CreateInfluencers to build an AI personality with a specific vibe, you'll need a collection of images that perfectly capture that style.
You can typically source data from a few common places:
- Public Datasets: Goldmines like Kaggle, Google Dataset Search, or Hugging Face have thousands of free datasets on just about any topic you can imagine. They're fantastic for getting your feet wet or for projects where collecting your own data is tough.
- APIs: Many services provide Application Programming Interfaces (APIs) that let you pull data programmatically. You could, for instance, tap into a social media API to collect posts about a new trend to train a model that understands public sentiment.
- Proprietary Data: This is the data your own business has collected—think customer purchase histories or user activity logs. This stuff is often the most valuable because it's completely unique to your situation.
Regardless of where it comes from, your initial dataset will be a mess. Don't worry, that's completely normal. The next job is to bring some order to that chaos.
The Gritty Work of Data Cleaning
Data cleaning is all about fixing or ditching incorrect, corrupted, poorly formatted, duplicate, or incomplete data. Think of it as setting the curriculum for your model's education. A model trained on messy data will only give you messy, unreliable answers.
Imagine you're building a model to predict house prices. Your raw data might have blank spots for the number of bathrooms or wild inconsistencies in how square footage is recorded (e.g., "1,500," "1500 sq ft," "1.5k"). An AI can't make sense of that kind of variability.
Key Insight: Ask any data scientist, and they'll tell you that data preparation—especially cleaning and labeling—can eat up to 80% of their time on a machine learning project. It’s a huge time investment, but it's non-negotiable if you want a reliable AI.
Common cleaning tasks usually involve:
- Handling Missing Values: You can either remove rows with missing data (if you have a large enough dataset) or "impute" them by filling in the blanks with a mean, median, or a more sophisticated statistical estimate.
- Removing Duplicates: Identical entries can skew your model's learning by giving certain data points more weight than they deserve.
- Correcting Inconsistencies: This is about standardization. You'll want to make sure all dates follow the same
YYYY-MM-DDformat or that all state names use the same two-letter abbreviation.
Sculpting Data with Feature Engineering
With your data sparkling clean, it's time to shape it into something a model can actually understand. This is feature engineering, and it’s a beautiful blend of art and science. It’s about using your industry knowledge to create new input variables (we call them features) that make the patterns in your data pop.
Let's say your data has a "purchase_timestamp" column. On its own, a raw timestamp isn't very helpful for a model. But from that one piece of information, you could engineer several powerful new features:
- Hour of the day: Are purchases more common in the morning or late at night?
- Day of the week: Do you see a spike in shopping over the weekend?
- Is_Holiday: A simple
TrueorFalseflag that could be a huge predictor.
These new features are far more insightful. At this stage, you also have to tackle different data types. Models are good with numbers, not so much with text. A "color" feature with values like "Red," "Blue," and "Green" needs to be converted into a numerical format, often using a technique called one-hot encoding.
This is also where you'll do normalization or scaling. This process rescales your numeric features to a standard range, like 0 to 1. It prevents features with huge values (like "annual_income") from drowning out the influence of features with smaller values (like "years_of_experience"). Spending quality time on these transformations is a critical step in learning how to make an AI model that truly performs.
Choosing the Right AI Model Architecture
Okay, your data is clean and prepped. This is where things get interesting. Now you have to pick the blueprint for your AI's brain—its model architecture. This isn't about finding the single "best" model out there, but finding the right one for what you're trying to accomplish.

The whole decision boils down to one simple question: What do you need this AI to do? Are you trying to predict a number that can change, like next quarter's revenue? Or are you trying to sort things into buckets, like flagging customer support tickets as "Urgent" vs. "General Inquiry"? Each job has a family of models that are tailor-made for it.
Matching the Model to Your Mission
Think of AI models like specialized tools in a workshop. You wouldn't grab a sledgehammer to hang a picture frame. In the same way, choosing the right architecture from the get-go will save you a world of headaches and is a huge factor in whether your AI model actually works as intended.
Let's look at a few common scenarios and the models I usually reach for first:
Predicting a Number (Regression): If your goal is to forecast a numerical value—say, a product's future price or website traffic—Linear Regression is a fantastic place to start. It's clean, simple, and great for finding straightforward relationships in your data.
Classifying into Groups (Classification): When you need to stick a label on something, like deciding if an email is spam or if a loan application should be approved, Decision Trees or Logistic Regression are my go-to's. They're great at creating clear, understandable rules for sorting data.
Finding Complex Patterns (Deep Learning): For the really heavy lifting—like image recognition, understanding human language, or creating a virtual personality with a platform like CreateInfluencers—you'll want to look at Neural Networks. These models are inspired by the human brain and are absolute masters at finding subtle, complex patterns in massive datasets.
Don't worry about getting it perfect on the first try. This part of the process is often iterative. I almost always start with a simpler model to get a baseline for performance before I even think about bringing out the more complex and resource-hungry options.
The Power of Pre-Trained Models
Here’s a pro tip: you don't always have to build your model from scratch. In fact, you probably shouldn't. One of the biggest game-changers in AI development has been transfer learning. This is where you take a powerful, pre-trained model—one that's already learned from a colossal dataset—and just fine-tune it using your own specific, smaller dataset.
It's like teaching a kid to recognize a zebra. It’s a lot easier if they already know what a horse looks like, right? A model pre-trained on millions of images already understands basics like edges, shapes, and textures. That foundation makes it incredibly fast to teach it your specific task.
This strategy is a massive shortcut, saving you a ton of time and computational power. The AI world is overflowing with these foundational models, thanks to an explosion in research from both academia and private industry.
The trend is clear: industry now produces nearly 90% of all notable AI models, a huge leap from just 60% the year before. This boom, driven by a tripling of AI publications in the last decade, has built a massive library of powerful models ready for you to adapt. If you want to dive deeper into these numbers, you can explore the full AI Index Report 2025.
Balancing Complexity and Cost
As you figure out how to make an AI model, you’ll constantly be making a trade-off. It’s a balancing act between a model's complexity, its potential accuracy, and the sheer resources it takes to run. Sure, a gigantic neural network might hit 99% accuracy, but if it requires a server farm the size of a small country to train, it’s probably not a practical solution.
Keep these factors in mind when you're weighing your options:
| Factor | Simpler Models (e.g., Linear Regression) | More Complex Models (e.g., Neural Networks) |
|---|---|---|
| Data Needs | Does well with smaller, well-structured datasets. | Needs huge amounts of data to learn effectively. |
| Training Time | Quick to train, often in minutes or hours. | Can take days, sometimes weeks, to train. |
| Interpretability | Easy to see why it made a certain decision. | Often a "black box"; its reasoning can be a mystery. |
| Performance | Great for clear, linear patterns in data. | Excels at finding incredibly complex, hidden patterns. |
Picking an architecture is a strategic move. Start by thinking about your end goal, seriously consider using a pre-trained model to save time, and be realistic about the resources you have. Nailing this step sets you up for a much smoother ride during the next phase: training and evaluation.
Training and Evaluating Your AI Model
Alright, your data is clean and you've picked a model architecture. Now comes the fun part. This is where your abstract plan becomes a tangible, learning machine that starts to uncover the patterns you’ve been looking for.
Don't think of training as a one-shot deal. It's more of an ongoing conversation with your model—a cycle of teaching, testing, and tweaking until it gets things right.
Think of it like this: your AI is studying for a big exam. Instead of cramming the night before, it reviews the material in manageable chunks, getting a little smarter with each pass. This iterative process is the absolute core of machine learning.
Getting the Training Loop Started
The entire training process is guided by a few critical settings called hyperparameters. These aren't just technical jargon; they're the knobs and dials you'll turn to influence how your model learns. Getting a feel for them is crucial for steering your model towards a great outcome.
Here are the main ones you'll be working with:
- Epochs: An epoch is one complete trip through your entire training dataset. If you have 10,000 images and you set the training for 10 epochs, the model will see and learn from all 10,000 of those images a total of ten times.
- Batch Size: It's inefficient to show the model all your data at once. Instead, we feed it in smaller groups, or "batches." A batch size of 32 means the model analyzes 32 data points, calculates how wrong it was, and updates its internal logic before moving on to the next batch of 32.
- Learning Rate: This is arguably the most important dial you can turn. The learning rate dictates the size of the adjustments the model makes after each batch. If it's too high, the model can learn erratically and overshoot the best solution. Too low, and the training will take forever.
Finding the sweet spot for these settings is more of an art than a science. It almost always involves some hands-on experimentation to figure out what works for your specific data and goals.
Don't Let Your Model "Cheat" by Memorizing
One of the biggest pitfalls in AI development is overfitting. This is what happens when your model gets so good at seeing the training data that it starts to memorize it—including all the noise and irrelevant details—instead of learning the actual underlying patterns.
An overfit model performs spectacularly on the data it was trained on but falls flat on its face when it sees new, real-world examples. It's like a student who memorized the answers to a practice test but can't solve a slightly different problem.
To catch this, we strategically split our dataset into three separate piles:
- Training Set: This is the lion's share, usually 70-80% of your data, used for the day-to-day learning process.
- Validation Set: This smaller slice (10-15%) acts as a periodic spot-check. You use it during training to see how well the model is generalizing and to help you fine-tune those hyperparameters.
- Testing Set: This final portion (10-15%) is kept under lock and key until the very end. You only use it once to get a final, unbiased grade on how the model will likely perform out in the wild.
Key Insight: Your validation set is your early-warning system. If you see the training accuracy climbing but the validation accuracy starts to stall or even drop, that’s a massive red flag for overfitting.
This separation is non-negotiable. It’s the only way to get an honest assessment of what you've actually built.
Measuring What Really Matters
So, how do you know if your model is any good? You need to define success with cold, hard numbers. The right metric to track depends entirely on what you're trying to accomplish.
This is where the staggering cost of training an AI model comes into play. Top-tier models like GPT-4 required computational power on the order of 10^25 floating-point operations (FLOPs), with a price tag in the tens of millions of dollars. As noted in research on trends in AI model compute costs from epoch.ai, the compute needed for training roughly doubles every eight months.
Wasting that kind of time and money because you were tracking the wrong metric is a painful mistake.
Choosing the Right Evaluation Metric
Choosing the right yardstick is critical. A model can look great on one metric and terrible on another. This table breaks down some common metrics and when you should be using them.
| Metric | Best For | Practical Example |
|---|---|---|
| Accuracy | Classification tasks with balanced classes. | A model identifying cat vs. dog photos where there's an equal number of each. |
| Precision | When false positives are very costly. | A spam filter; you'd rather a spam email slip through (false negative) than a critical work email being marked as spam (false positive). |
| Recall | When false negatives are very costly. | A medical model detecting a disease; you'd rather have a false alarm (false positive) than miss an actual case (false negative). |
| Mean Squared Error (MSE) | Regression tasks where you're predicting a number. | A model predicting house prices; this metric heavily penalizes large errors, pushing the model to be more accurate on outliers. |
Knowing how to interpret these numbers is what separates a novice from an expert. This whole cycle—train, measure, tweak, repeat—is the true heartbeat of building an effective AI model.
Putting Your AI Model to Work in the Real World
You've built and trained your model. It's accurate, it's powerful... but right now, it's just a file sitting on your computer. To get any real value out of it, you need to put it out in the world where it can actually do its job. This is the final and most exciting phase—transforming your hard work from an interesting experiment into a tool that people and systems can interact with.

Before we flip the switch, there's one last bit of refinement that can give your model a significant performance boost: hyperparameter tuning. Think of it as the final calibration. We're talking about making small, strategic tweaks to the model's configuration—things like the learning rate or batch size we touched on earlier—to squeeze out every last drop of accuracy.
This is usually an automated process where you run through dozens or even hundreds of setting combinations, letting the system find the optimal mix that performs best on your validation data. It’s like a concert violinist meticulously tuning their instrument right before a performance. The music is already there, but this final adjustment ensures it hits every note perfectly.
Picking Your Deployment Strategy
With a fully tuned model in hand, it’s decision time. How are you going to make it accessible? The answer really depends on how you plan to use it. Is this for a website? An internal business tool? A mobile app?
Here are the most common paths people take:
- API Endpoint: This is by far the most flexible and widely used method. You essentially wrap your model in an API (Application Programming Interface), which lets other applications send it data and get a prediction back. For example, a website could send a new user comment to your sentiment analysis model through an API call and get an instant "positive" or "negative" label in return.
- Direct Embedding: For apps that need lightning-fast responses or have to work offline, you can embed the model file directly into the software. A perfect example is the camera app on your phone that suggests settings in real-time. That model is running on your device, not some far-off server.
- Batch Processing: Sometimes, you don't need answers in real-time. If you have a massive dataset to chew through—say, sorting thousands of product images overnight—you can run the model as a batch job. It processes everything at once and saves the results for later.
Choosing the right strategy is a huge part of learning how to make an AI model that actually fits into a real workflow. For creators building interactive AI personalities on a platform like CreateInfluencers, the API approach is a no-brainer. It's what allows for those dynamic, real-time conversations.
Don't Deploy and Forget: Keeping an Eye on Your Model
Getting your model live isn't the finish line. In fact, it's just the beginning. You have to monitor its performance constantly, because the world changes, and a model that was brilliant yesterday might start to falter tomorrow.
This happens because of something we call concept drift. It’s the natural tendency for a model's predictive power to weaken over time as the real-world data it encounters starts to look different from its training data. A model trained on 2022 fashion trends will quickly become useless as new styles emerge.
Key Takeaway: Think of a deployed AI model as a living system, not a static artifact. You absolutely need a plan for continuous monitoring and retraining to keep it accurate and useful for the long haul.
To stay ahead of concept drift, you need a solid monitoring plan. This typically involves:
- Logging Predictions: Always keep a record of the inputs the model receives and the predictions it makes.
- Tracking Key Metrics: Continuously measure performance metrics like accuracy or precision against live data.
- Setting Up Alerts: Create automated notifications that tell you when the model's performance dips below an acceptable threshold.
When you see a significant performance drop, that's your cue. It's time to head back to the training stage with fresh, relevant data to bring your model back up to speed. This cycle of deploying, monitoring, and retraining is the secret to ensuring your AI remains a powerful and reliable asset long after its launch day.
Frequently Asked Questions About Creating AI Models
Stepping into the world of AI development often brings up more questions than answers. As you start to build your own models, you'll run into a lot of new terminology and concepts. This section is designed to tackle some of the most common hurdles and give you clear, straightforward answers so you can move forward.
How Much Data Do I Really Need?
This is the million-dollar question, and the honest answer is, "it depends." There’s no magic number. The right amount of data is tied directly to how complex your problem is.
For a pretty straightforward task, like predicting house prices based on a few key factors (think square footage, number of bedrooms, and location), you can often get solid results with just a few hundred clean data points. The relationships are clear, making it easier for a model to find the patterns.
But when you jump into more complex territory, the data needs to grow exponentially. If you’re training a deep learning model for image recognition or crafting a detailed AI personality on a platform like CreateInfluencers, you’re talking about thousands, or even millions, of examples. The more nuance and variables involved, the more data your model needs to learn effectively.
A Good Rule of Thumb: It's always better to start with a smaller, high-quality, and meticulously cleaned dataset than a massive, messy one. Quality beats quantity, especially in the early stages.
What's the Difference Between AI, Machine Learning, and Deep Learning?
People often use these terms interchangeably, but they actually describe concepts nested inside each other. The easiest way to think about it is with a set of concentric circles.
- Artificial Intelligence (AI): This is the big, all-encompassing outer circle. AI is any technique that lets a computer mimic human intelligence, from simple "if-then" rules to complex reasoning.
- Machine Learning (ML): This is a key subset of AI. ML is all about algorithms that learn from data to find patterns and make predictions without being explicitly programmed. You don't write the rules; you feed it data and let it figure things out on its own.
- Deep Learning (DL): This is an even more specialized slice of Machine Learning. Deep Learning uses complex, multi-layered neural networks—structures inspired by the human brain—to learn from huge amounts of data. It’s the powerhouse behind recent breakthroughs like large language models and photorealistic image generation.
Can I Make an AI Model Without Coding?
Absolutely. The old idea that you need to be a coding wizard to build AI is fading fast. The rise of no-code and low-code AI platforms has thrown the doors open for creators, marketers, and entrepreneurs.
These platforms give you an intuitive, visual interface that walks you through the entire process. You can typically:
- Upload your dataset.
- Choose what you're trying to do (like classification or regression).
- Select a model with a simple click.
- Start the training and watch its progress in real-time.
While coding will always give you the most control for highly customized projects, no-code tools are an incredibly powerful way to build and launch production-ready models for a massive range of real-world business needs.
How Can I Tell if My AI Model Is Biased?
Spotting and fixing bias is one of the most critical parts of building a responsible AI model. Bias isn't just a technical bug—it's a reflection of flawed data or human assumptions that can have serious, real-world consequences.
The problem almost always starts with the training data. If your dataset doesn't include enough representation from certain groups or contains historical prejudices (like old, biased hiring decisions), your model will learn and often amplify those same biases.
To catch this, you need to start by analyzing your dataset for imbalances before you even start training. Once your model is built, the real test is to evaluate its performance across different subgroups. For example, does your facial recognition model work equally well for people of all ethnicities? If you see a big gap in accuracy between groups, that's a huge red flag. Fixing it often means going back to collect more representative data or using specific techniques designed to promote fairness during training.
Ready to build your own AI without getting lost in the code? With CreateInfluencers, you can generate unique AI personalities, images, and videos in just a few minutes. Start creating for free and bring your vision to life today!